Data warehousing is not a new concept as it is about multiple processes stitched together to consolidate data from several data sources, store them in a common format, and transform the data to fit the needs of various business entities. It is one of the most critical infrastructures as it caters data to the organization to get important insight.
Traditional data warehouses in a way can not keep up the pace of new data generation and in different formats too. On top of ingesting data from multiple formats into one consolidated format, there is this overhead of regular patches, and significant time and resources to keep it running. Amazon Redshift provides one of the best data warehouse solutions to get away from those overheads.
Amazon Redshift is an enterprise-grade data warehouse system that is fully managed in the AWS cloud. It is essentially a relational database and provides typical Relational Database Management System (RDBMS) functionalities. Amazon Redshift is based on PostgreSQL and is optimized primarily for online analytic processing (OLAP) and business intelligence (BI) applications. There are however significant differences between PostgreSQL and Amazon Redshift as the latter is built to different requirements. To provide faster analytical query processing on very large and complex datasets, Amazon Redshift stores data in columnar format using special data compression for the best I/O. Also, certain features of PostgreSQL like having secondary indexes and single-row data operations have been removed from Amazon Redshift to gain analytical query processing gains over a large record set.
Amazon Spectrum provides another option for the data warehouse to be able to query and analyze a large volume of structured and unstructured data from Amazon S3 without the need to load the data in Amazon Redshift using Massively Parallel Processing (MPP).
There are various elements to the Amazon Redshift Data Warehouse as highlighted in the figure below.
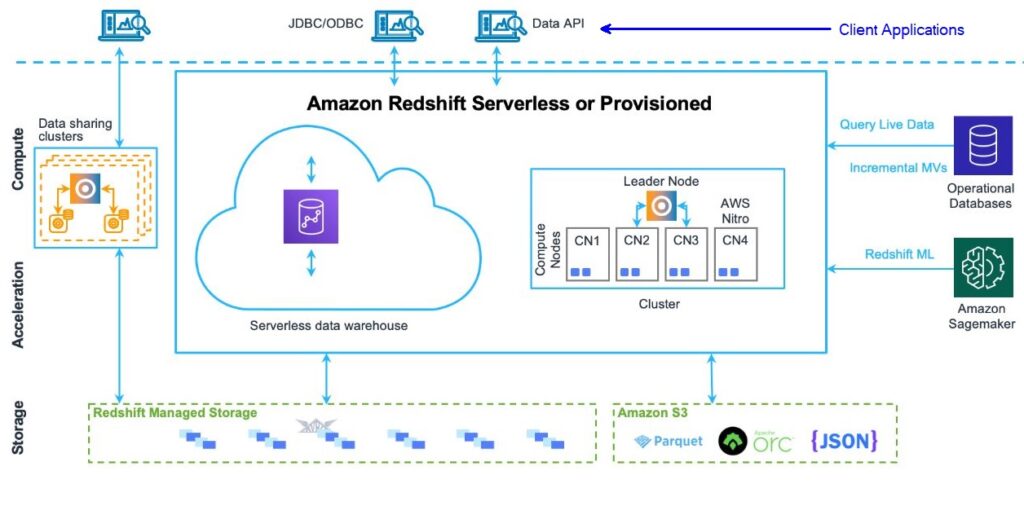
Image Source
Storage
Amazon Redshift stores data separately in Redshift Managed Storage (RMS) which can extend the storage to use Amazon S3 storage. RMS decouples storage and computing which allows organizations to scale independently.
Redshift Cluster
Nodes are essentially a collection of resources for computation. Amazon Redshift organizes those nodes in a group called Cluster which is its core component. Each cluster contains at least one database and all user data is stored on the compute node. A leader node is needed when the cluster has two or more compute nodes.
- Leader Node – All the client applications interact with the leader nodes as it manages all the communications with the compute nodes and the client applications. The leader node parses and creates the execution plan for all the queries and distributes them to the compute nodes to get the results back.
- Compute Nodes – The compute nodes run those compiled codes and send results back to the leader node which then does the final aggregation. Compute nodes have their own dedicated resources (CPU, Memory) which can be scaled up and down depending on the requirements. Each compute node is further partitioned into slices called Node slices and the number of slices per node is dependent on the cluster size. Node slices have certain resources (memory, storage) allocated to them to process the workload assigned to the corresponding node. The leader node distributes data to node slices and allocates the query workload. The node slices work in parallel and complete the operation returning the results for aggregation.
Client Applications
Amazon Redshift works well with several ETL tools and BI applications for data analysis, AI/ML modeling, and data visualization. SQL client applications will work with Amazon Redshift with almost no changes or minimum changes. Data in Amazon Redshift can be shared securely with clients or connected directly via different drivers (JDBC/ODBC) or using Data API.
Why is Amazon Redshift fast?
Amazon Redshift incorporates a query engine that leverages Massively Parallel Processing (MPP), caches certain results on the leader node, and takes advantage of columnar data storage. Loading the data from files or distributing the rows of a table to the compute node are all handled in parallel. Amazon Redshift stores data in columnar orientation which gains the maximum data compressions and significantly reduces the disk I/O by avoiding trips back to the disk.
Moving data within AWS/Other services and Amazon Redshift
Amazon Redshift integrates well with other several AWS services that enable data to be moved, enriched, and consumed.
- Amazon S3 – Amazon Simple Storage Service (S3) is cloud storage. Amazon Redshift can read and load data from files stored in Amazon S3 or can also export data from Amazon Redshift tables to data files on Amazon S3.
- Amazon DynamoDB – It is a NoSQL database as a service fully managed in the cloud. Use the COPY command to load data from a DynamoDB table to an Amazon Redshift table.
- Remote hosts – Amazon Redshift can load data from several remote hosts like Amazon EMR cluster, EC2 instances, or other hosts by simply using the COPY command to connect to hosts using SSH.
AWS Database Migration Service (AWS DMS) can migrate data to and from databases like MS SQL Server, PostgreSQL, MySQL, Oracle, Amazon Redshift, DynamoDB, and MariaDB.
AWS Data Pipeline can be used to automate data loading and transformation in and out of Amazon Redshift. The AWS Data pipeline has native capabilities to schedule and run jobs that can transfer and transform your data.