The modern data ecosystem is like a real estate market for your bytes except instead of bidding wars, we’ve got schema-on-write vs. schema-on-read drama. Let’s break down the contenders: Data Warehouses, Data Lakes, Lakehouses, and crack open the open table format.
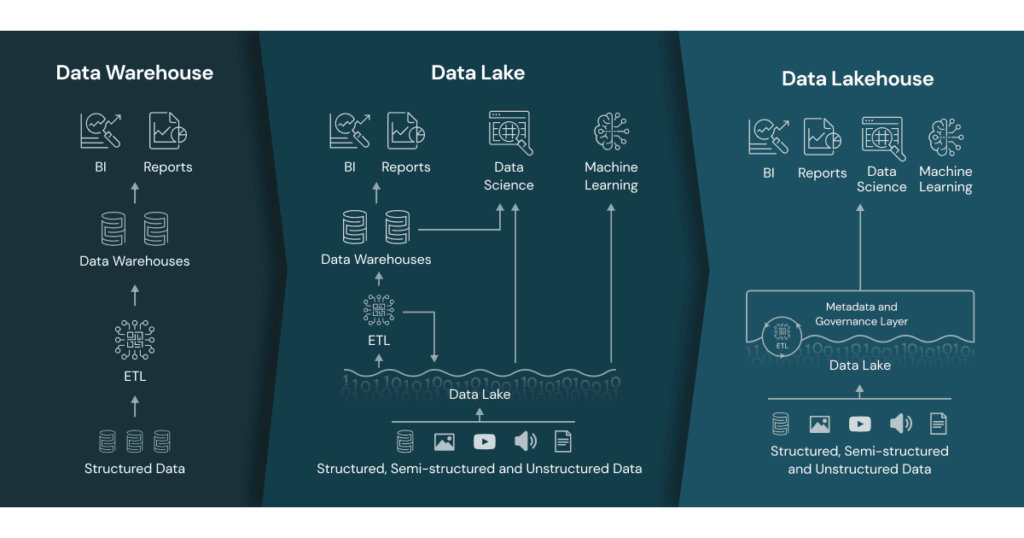
1. Data Warehouses: The Neat Freaks of Data
Born in the 1990s, data warehouses are the Marie Kondo of data storage. They demand structure: “Does this CSV spark joy? No? Transform it before it enters!”
- Schema-on-Write: Data must be cleaned, formatted, and validated before ingestion. Think of it like a bouncer at a club – only VIPs (Very Important Parquets) get in.
- Use Case: Perfect for BI dashboards. Example: A retail company funneling sales data into Snowflake to track daily revenue.
- Downsides: Costs can balloon faster than a TikTok influencer’s follower count. Plus, unstructured data (like cat memes) need not apply.
Pro Tip: Modern cloud warehouses (Snowflake, Redshift, BigQuery, Databricks) decouple storage and compute. Translation: You no longer need to sell a kidney to scale.
2. Data Lakes: The Hoarders of Raw Data
Data lakes arrived in the 2010s as the “no rules, just vibes” alternative. They’ll store anything, JSON logs, cat videos, even your ex’s Spotify playlists.
- Schema-on-Read: Data is raw until queried. It’s like tossing everything into a garage and declaring, “I’ll organize it later.” (Spoiler: You won’t.)
- Use Case: A healthcare provider dumping MRI scans and patient records into Amazon S3 for “future research” (aka we’ll figure it out someday).
- Downsides: Without governance, lakes become data swamps – a murky mess where metadata goes to die.
Pro Tip: To avoid swamps, add Apache Spark (the data equivalent of a Hazmat suit).
3. Lakehouses: The Best of Both Worlds… Or a Unicorn?
Lakehouses are the Tesla Cybertruck of data storage – promising to merge warehouses and lakes, but leaving everyone asking, “Does this actually work?”
Key features:
- ACID Transactions: For when you need your data as reliable as a golden retriever.
- Open Formats: Delta Lake and Iceberg let you query data with SQL and train ML models.
- Use Case: A fintech firm analyzing real-time transactions (silver layer) while serving dashboards (gold layer).
The Catch: Lakehouses require more metadata management than a Taylor Swift fan account. Tools like Unity Catalog, Polaris are a must.
| Feature | Data Warehouse | Data Lake | Lakehouse |
|---|---|---|---|
| Data Types | Structured | All | All |
| Schema Enforcement | Schema-on-Write | Schema-on-Read | Optional |
| Transactions | ACID | None | ACID |
| Use cases | BI, Reporting | ML, Raw Storage | BI + ML |
| Cost | High (Compute + Storage) | Low (Storage) | Moderate |
4. The Open Table Format: Delta Lake vs. Hudi vs. Iceberg
If Delta Lake, Hudi, and Iceberg were superheroes, they’d all have the same mission: Rescue data lakes from chaos. But each has its own superpower. Let’s demystify them:
Delta Lake: The Reliable Workhorse
- Origin Story: Born at Databricks, Delta Lake is the OG of lakehouse reliability. It’s like adding seatbelts and airbags to your data lake.
- Superpowers:
- ACID Transactions: Ensures data writes are Atomic, Consistent, Isolated, Durable (no “half-baked” Parquet files).
- Time Travel: Roll back to previous versions of your data, because even data engineers make mistakes.
- Schema Enforcement: “You shall not pass!” – unless your data matches the schema.
- Best For: Teams already using Databricks/Spark, or those who want seamless integration with ML workflows.
- Signature Move: The medallion architecture (bronze → silver → gold layers).
Apache Hudi: The Real-Time Maverick
- Origin Story: Created by Uber to handle real-time ride-sharing data. Hudi is like a caffeine-powered courier – built for speed and freshness.
- Superpowers:
- Upserts: Update or delete records in your data lake (no more “full table rewrites”).
- Incremental Processing: Only process new data, saving time and $$$.
- Compaction: Automatically optimize small files (no more “junk drawer” storage).
- Best For: Real-time pipelines (e.g., IoT, fraud detection) or frequent updates (e.g., GDPR “right to be forgotten” requests).
- Signature Move: Copy-on-Write (updates create new files) vs. Merge-on-Read (combines base + delta files at query time).
Apache Iceberg: The Swiss Army Knife
- Origin Story: Hatched at Netflix to solve “hidden partition” nightmares. Iceberg is like a GPS for your data lake – no more getting lost in nested folders.
- Superpowers:
- Partition Evolution: Change how your data is partitioned without breaking existing queries.
- Schema Evolution: Add/rename columns without rewriting terabytes of data.
- Engine Agnostic: Plays nice with Spark, Trino, Flink, and even Snowflake.
- Best For: Multi-engine environments (e.g., Spark + Trino) or teams that hate vendor lock-in.
- Signature Move: Hidden Partitioning – query data by column (e.g., date) without caring how it’s physically stored.
| Feature | Delta Lake | Apache Hudi | Apache Iceberg |
|---|---|---|---|
| Primary Use Case | Batch + Streaming | Real-time | Multi-engine analytics |
| ACID Transactions | ✅ | ✅ | ✅ |
| Time Travel | ✅ | ✅ | ✅ |
| Schema Evolution | ✅ (enforcement) | ✅ | ✅ (no rewrites) |
| Partition Flexibility | Limited | Moderate | ✅ Hidden Partitioning |
| Ecosystem | Spark-centric | Spark/Flink | Engine-agnostic |
Why This Matters for Lakehouses
All three formats turn data lakes into lakehouses by adding:
- Reliability: ACID transactions prevent “data corruption anxiety.”
- Performance: Faster queries via metadata optimization (no more “WHERE clause roulette”).
- Flexibility: Evolve schemas and partitions without summoning the data exorcist.
The modern data stack isn’t about choosing one format, it’s about picking the right tool for the job:
- Use Delta Lake if you’re married to Spark/Databricks.
- Pick Hudi for real-time pipelines (or if you’re an Uber fanboy).
- Choose Iceberg for engine-agnostic flexibility (or if you’re Netflix-level paranoid about lock-in).
All three prove that lakehouses aren’t just hype – they’re the future. Just don’t let your data lake turn into a swamp while you’re busy debating formats.
Challenges and Considerations
- Governance: Lakehouses require robust metadata tools (e.g., Unity Catalog) to avoid silos.
- Skill Gaps: Transitioning from SQL-centric warehouses to Spark/Python workflows demands retraining.
- Hybrid Stacks: Many enterprises retain warehouses for mission-critical BI while offloading ML to lakehouses.
Conclusion
The modern data stack is not a zero-sum game. Data warehouses remain optimal for structured BI, lakes for raw storage, and lakehouses for unified analytics. Delta Lake bridges reliability gaps in lakes, enabling lakehouse architectures. Leaders must evaluate trade-offs:
- Use warehouses for low-latency SQL.
- Adopt lakehouses with open table format for ML/AI scalability.
- Leverage medallion architectures to enforce quality in multi-layered workflows.
The future lies in integrated platforms that democratize data access while maintaining rigor. By strategically combining these paradigms, organizations can build agile, future-proof stacks.