dbt: The Data Engineer’s Superhero Sidekick
Let’s face it: writing SQL is fun… until you’re juggling 47 versions of the same query, hunting down broken dashboards, or explaining to your boss why “revenue” means three different things. Enter dbt (data build tool), the Swiss Army knife of data transformation that turns SQL chaos into zen-like order. Think of it as Git for your data pipelines, but with fewer existential crises.
Why dbt? Because Copy-Pasting SQL is So 2010. dbt isn’t just a tool – it’s a lifestyle upgrade for data teams. Here’s why:
- Modular Madness: Write SQL once, reuse it everywhere. No more
SELECT * FROM that_one_table_joanna_made_last_quarter.sql. - Version Control FTW: Collaborate without accidentally nuking the “
final_final_v3” model. Branch, PR, and deploy like a software engineer (minus the hoodie). - Docs That Don’t Suck: Auto-generate documentation so good, even your PM will understand why “
monthly_active_users” excludes bots namedXx_DataLover13_xX.
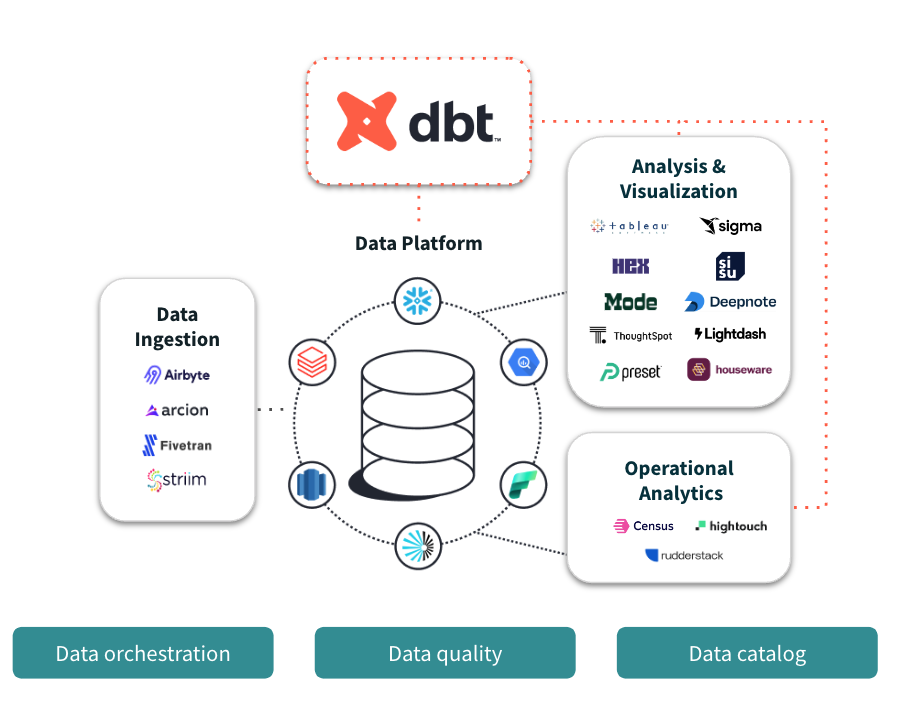
dbt Core vs. dbt Cloud: Choose Your Adventure
dbt Core (For the DIY Crowd)
- Open-source freedom! Perfect if you love terminals, YAML files, and yelling “IT WORKS ON MY MACHINE!”
- Quickstart: Install via CLI, then spend 3 hours Googling why your Jinja macro won’t compile. Kidding… mostly.
dbt Cloud (For the “I Have Deadlines” Crowd)
- Fully managed bliss: Develop, test, schedule, and cry over failed runs – all in one shiny UI.
- Pricing: Free to start, then scales with your ego (and data volume).
dbt’s Greatest Hits
Materializations Made Easy
Turn SELECT statements into tables/views with a config flag. No more hand-writing DDL like a medieval scribe.
{{ config(materialized='table') }}
SELECT * FROM {{ ref('raw_chaos') }}
Jinja Magic
Add loops, conditionals, and macros to SQL. Because why shouldn’t SQL have a little pizzazz?
{% for department in ['sales', 'marketing', 'engineering'] %}
SELECT * FROM {{ department }}_metrics
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}
Tests That Actually Work
Catch NULLs, duplicates, and sad data before your CEO spots them.
- unique: column_name: user_id - not_null: column_name: signup_date
Snapshots for Drama-Free History
Track slowly-changing dimensions without needing a PhD in temporal logic.
Why You’ll Love dbt
- No More Boilerplate Hell: Let dbt handle transactions, drops, and schema changes. You focus on the what, not the how.
- Incremental Models: Speed up pipelines by only updating new data. Your warehouse bill (and sanity) will thank you.
- Community Vibes: Join 50k+ data nerds in Slack who’ve also cried over a GROUP BY error at 2 AM.
dbt Projects Explained
Let’s talk about dbt projects – the “IKEA manual” for transforming your data chaos into something resembling order. Think of a dbt project as your data team’s recipe book: it tells dbt what to cook (your data), how to cook it (SQL/Python), and where to store the leftovers (your warehouse).
What’s Inside a dbt Project?
- The Rulebook (dbt_project.yml)
- The only mandatory file. It’s like the “adult Lego instructions” for your project.
- Defines your project’s name (in snake_case, because CamelCase is for cowards), dbt version limits, and where to find stuff.
- The Chaos Containers (Directories)
- Analyses: Where SQL rebels hang out – too cool for model school. For queries that say, ‘I’ll compile, but I won’t run
- Macros: Reusable code blocks – because copying SQL 47 times is so 2010.
- Models: SQL files that turn raw spaghetti into structured lasagna.
- Seeds: CSV files you drag in like a kid’s school project (“Look, I loaded static data!”).
- Snapshots: Time capsules for tracking how your data looked before someone broke it.
- Tests: SQL checks to confirm your data isn’t lying. “Find if revenue is actually a number?
- Docs: Where code goes for therapy. Contains 100% of your typos and 0% of our regrets.
How to Organize This Madness
dbt lets you structure your project however you want, but here’s how to avoid becoming “that person”:
- For Developers: Group models by department (marketing/, finance/).
- For Stakeholders: Use docs/ to explain why “monthly_active_users” excludes your CEO’s cat.
- For Your Sanity: Bulk-configure models in dbt_project.yml so you don’t have to micromanage every SQL file.
Key YAML Settings For Your dbt_project.yml File (For People Who Hate YAML)
name: 'my_project' # Your project’s name, but snake_case (because CamelCase is for cowards)
version: '1.0.0' # Fake it till you make it
config-version: 1
# This setting configures which "profile" dbt uses for this project.
profile: 'prod' # The warehouse you’re terrorizing today
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In dbt, the default materialization for a model is a view. This means, when you run
# dbt run or dbt build, all of your models will be built as a view in your data platform.
# The configuration below will override this setting for models in the example folder to
# instead be materialized as tables. Any models you add to the root of the models folder will
# continue to be built as views. These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
my_project:
+materialized: table
Project Subdirectories
Tired of your dbt projects elbowing each other in the repo like siblings in a minivan? Project subdirectory is here to assign them their own zip codes.
What’s the Deal?
- Organize Chaos: Keep projects in tidy folders (e.g., /finance, /teams/marketing).
- Avoid Identity Crises: Tell dbt Cloud, “Hey, my stuff’s over here!” so it stops rootling through your entire repo like a raccoon in a trash can.
How to Set It Up (Without Crying)
- Summon the Settings Wizard: Click the ⚙️ → Account Settings → pick your project.
- Drop the Map Pin: In Project subdirectory, type the folder path (e.g., teams/finance).
- Pro Tip: Skip the /’s. dbt’s not fancy.
- Save & Pray: Hit Save. If dbt whines about dbt_project.yml, go write one. It’s the project’s birth certificate.
Aftermath
- dbt run/test now only haunts your subdirectory.
- Your repo stays cleaner than a Marie Kondo closet.
Go forth and compartmentalize! Your future self (and teammates) will thank you.
The Bottom Line
dbt is like duct tape for your data stack – it holds everything together while making you look like a genius. Whether you’re a SQL newbie or a warehouse wizard, dbt turns “hot mess” into “hot damn, that’s clean!”
Ready to ditch SQL spaghetti? Try dbt Cloud or go rogue with dbt Core. Your future self will high-five you.