I’ve spent countless hours exploring new data tools, only to find myself overwhelmed by the sheer number of options – many promising to solve the same problems in slightly different ways. As data volumes grow, so does the complexity of managing and analyzing it efficiently. The challenge isn’t just keeping up, it’s figuring out which tools truly fit within your data ecosystem without adding unnecessary overhead.
This is where the Modern Data Stack comes in. It’s a term that gets thrown around a lot, but what does it really mean? I took a deep dive to break it down and put together an inventory list to help navigate this ever-evolving landscape
The modern data stack (MDS) is a cloud-native ecosystem comprising tools for data ingestion, storage, transformation, analytics, orchestration, governance, and monitoring. It is designed to handle the end-to-end lifecycle of data, enabling businesses to derive insights efficiently and make informed decisions. MDS will help the organizations handle the growing complexity of data-driven operations.
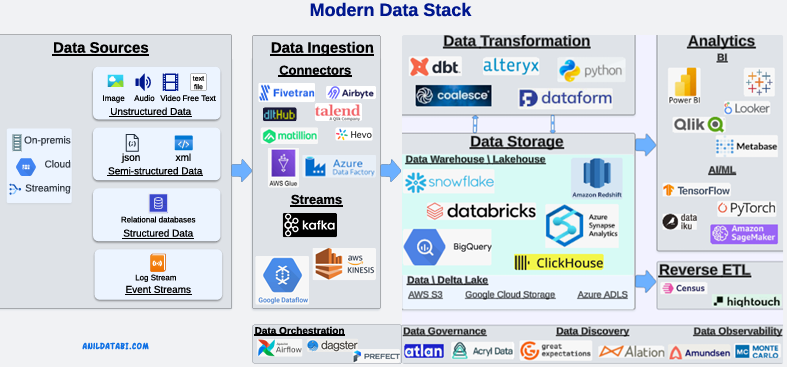
Components of the Modern Data Stack
- Data Sources
- Data Ingestion
- Data Storage
- Data Transformation
- Data Analytics
- Data Orchestration, Governance, and Monitoring
- Reverse ETL
Data Sources
Every organization generates or collects data from several sources. This data can be:
- Structured: Highly organized and formatted, such as relational databases.
- Semi-structured: Data with some structures, like JSON, XML, CSV files.
- Unstructured: Data without any predefined format, such as texts, images, videos or sensor data.
This data may originate from cloud platforms, on-premises infrastructure, or IoT devices.
Data Ingestion
Data ingestion involves collecting data from diverse sources and consolidating it into a unified system for analysis and decision-making. Modern tools like Apache Kafka, Fivetran, Airbyte, or AWS Glue enable efficient ingestion of data into target storage location. Data ingestion using ETL/ELT tools provide:
- Support for batch and real-time processing
- Connectivity with various data sources like APIs, databases, and streaming platforms
Data Storage
Data storage solutions help organizations manage and analyze large volumes of data effectively. The traditional data warehouse solutions with rigid schema is evolving and the use of a new Lakehouse architecture is getting popular. A bit out of scope but let’s review these data management solutions.
– Data Warehouse
It is a centralized repository designed to store and analyze structured data. It organizes data into predefined schemas, optimizing it for business intelligence (BI) and reporting. Data warehouses excel at running complex SQL queries, aggregating data, and providing consistent, high-performance insights for decision-making.
Key features of a data warehouse include:
- Structured Data Storage: Stores data in well-defined tables with fixed schemas.
- Optimized Query Performance: Designed for fast analytical queries and reporting.
- Data Consistency: Ensures data accuracy and integrity through strong governance mechanisms.
While data warehouses are powerful for structured analytics, they face critical challenges in modern, data-rich environment.
- Rigid schema: Not well suited for modern use cases like data science, ML, and streaming analytics.
- High storage and compute costs: As the data volumes grow rapidly, it results in high costs.
- Lack of support for advanced workloads: Data warehouses are SQL-based analytics and not designed for large-scale ML or real-time processing limiting advanced analytics.
– Data Lake
It is a central repository for storing and processing raw data in any size or format. It is designed for flexibility, allowing diverse data streams (structured, semi-structured, and unstructured) to flow into a single location without requiring predefined structuring or expensive pre-processing.
Key characteristics of a Data Lake include:
- Flexibility: Data is stored in its original format, enabling a wide range of analyses without prior structuring.
- Multiple Data Sources: Supports ingesting data from various sources in real-time or batch processes.
- Cataloging and Indexing: Provides an organized overview of stored data for easy discovery.
- Team Collaboration: Allows access for multiple teams to use data for downstream tasks.
- Support for Data Science and Machine Learning: Enables advanced analytics directly on raw data.
Unlike data warehouses, which are optimized for specific structured queries and often involve proprietary formats (risking vendor lock-in), data lakes prioritize openness and flexibility. For example, a local directory of Parquet files or an S3 bucket containing tables, JSON files, and multimedia can function as a Data Lake, making it a cost-effective and versatile solution for modern data needs.
– Delta Lake
It is an open-source table format designed to enhance the reliability, performance, and flexibility of traditional data lakes while maintaining their cost-effectiveness. It introduces features commonly found in data warehouses, including:
- ACID Transactions: Ensures reliable reads and writes.
- High-Performance Queries: Improves query speeds with file-skipping and optimized data organization.
- Data Versioning and Time Travel: Enables access to and recovery of previous versions of the data.
- Schema Enforcement and Evolution: Supports maintaining and adapting schemas as data changes over time.
- Flexible Data Operations: Offers advanced operations like DELETE, UPDATE, and column management.
Delta Lake works on top of existing data lake infrastructures (e.g., Parquet-based lakes) by adding a transaction log that tracks all changes and organizes data for optimal query performance. This combination makes Delta Lake a foundational component for building a Lakehouse architecture, which merges the flexibility of a data lake with the reliability and speed of a data warehouse.
– Lakehouse
It is a modern data architecture that combines the best features of data lakes and data warehouses into a single platform. It provides the flexibility and scalability of a data lake with the performance, reliability, and structure of a data warehouse. Lakehouses enable organizations to store all types of data (structured, semi-structured, and unstructured) in open formats while supporting advanced analytics, machine learning, and real-time processing.
Data Transformation
Data transformation involves converting raw data into a usable format to meet the needs of data scientists, analysts, and business users. Modern tools like dbt, dataform, etc. enable transformations directly within data warehouses, allowing organizations to:
- Clean and enrich data.
- Reshape datasets for specific use cases.
- Ensure data is analysis-ready.
Data Analytics
Data analytics enables businesses to extract actionable insights from curated datasets. Modern analytics platforms, such as Power BI, Tableau, and Looker, empower users to:
- Visualize trends and patterns.
- Generate predictive models using machine learning.
- Make data-driven decisions to shape strategic goals.
Advanced analytics and AI/ML tools further enhance decision-making by delivering predictive and prescriptive insights.
Data Orchestration, Governance, and Monitoring
Efficient data workflows require robust orchestration, governance, and monitoring practices:
- Data Orchestration – Coordinate and automate data workflows across diverse systems and environments. Manages interdependent workflows across multi-cloud environments. Tools like Apache Airflow and Prefect automate scheduling and execution.
- Data Governance – Framework of policies, processes, and standards that ensure the proper management, quality, security, and privacy of an organization’s data. Ensures compliance with privacy regulations (e.g., GDPR, CCPA). Focuses on maintaining data quality, security, and integrity across the platform.
- Data Monitoring – Continuous observation, collection, and analysis of data to ensure the performance, security, and accuracy of systems and processes. Tracks the health, performance, and reliability of data pipelines. Identifies and resolves issues to maintain operational efficiency.
Reverse ETL
Reverse ETL is a technology that extracts cleaned and processed data from a data warehouse and syncs it into business applications. For business users working on their business applications like Salesforce, Freshservice, etc. having relevant aggregated data readily available in their own daily tools can make all the difference.
Traditionally, data flows into a data lake/warehouse for analysis, but with Reverse ETL, it can be synced back into these tools, enriching their functionality.
Solutions like Hightouch and Census help businesses push insights from their warehouse into SaaS applications. For example, an account manager using Salesforce can access real-time product usage data, making it easier to prioritize leads and personalize outreach. Reverse ETL ensures teams have the right data where they need it most – without switching platforms.
Conclusion
The modern data stack is a comprehensive approach to managing the complexities of today’s data landscape. It continues to evolve, driven by innovations in cloud technology and the growing demand for real-time, actionable insights. By leveraging its components, organizations can streamline data operations, derive deeper insights, and drive business innovation.