Digital transformation is critical in today’s age to stay competitive. This requires a powerful data management strategy to oversee data integrity & quality, security, and integration with all different data sources. On-premise data solutions might have sufficed in the past but the trend now is moving towards a cloud-based solution and rightfully so due to all bells and whistles that include flexibility and scalability. Companies that want to transition from their on-prem solution to the cloud should consider several factors before making the jump.
Before migrating to Azure Synapse Analytics or to any modern cloud data warehouse solutions, consider the following:
- Migrating to cloud solutions requires changes in the current design. Make sure those changes are reviewed and scoped for implementation. The bigger question is – do you really need the power of these modern cloud solutions that deliver enterprise-class data warehouses? If the answer is Yes, then it might be worth it else stick to your current solution that has been working to be cost effective or try SQL Database in Azure.
- How big is your data? Do you need analytics on a very large dataset from structured/unstructured data sources?
- Is any machine learning required? and more to be tailored to your needs and requirements…
Let us look at Azure Synapse Analytics Architecture
Microsoft keeps everyone guessing with their new fancy names for technologies as their new release which in reality might be an existing one under the hood. If you were used to hearing Azure SQL Data Warehouse, then Azure Synapse Analytics should not be a surprise to you.
Azure Synapse is not a single service but rather a set of integrated Azure Data Services that brings in data ingestion, storage, and transformation to data science and visualization together in one platform.
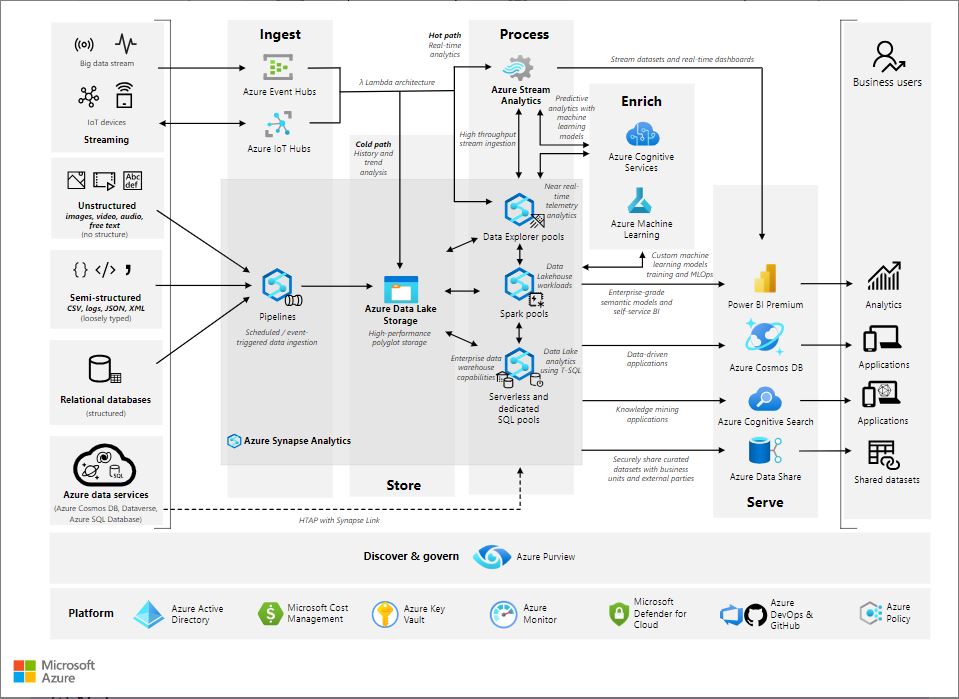
Image Source
The above architecture may look busy and overwhelming at first as it includes several Azure data services which by the way is still only a subset of much larger Azure services. However, this does not mean that to implement an Azure Synapse Analytics solution all of the above services need to be included. The choice of services is solely dependent on your need and how you want to implement modern data warehousing and analytics solutions.
Key components of Azure Synapse Analytics
Azure Synapse Studio is a web-based IDE that provides a unified user experience for all, data ingestion, warehousing, and other analytics tasks. There are several components that make Azure Synapse a unified platform. The core components are:
- Ingestion
- Storage
- Transform/Enrich
- Serve
Ingestion
If you have been doing SSIS as your ETL/ELT tool then consider Synapse Pipelines as SSIS in the cloud which shares its code base with Azure Data Factory. It provides a code-free environment to connect to several data sources and transform and load the data using built-in functionalities. It is part of the Synapse workspace where you can create and manage the data pipelines.
Pull data from a wide variety of sources including databases (on-prem, cloud), No-SQL databases, files (audio, video, image, etc.), and more using Azure Synapse Pipelines. To ingest data streams from client applications, leverage Azure Events Hubs/IoT Hubs.
Storage
All the data whether structured or not are stored in a single central location called a Data Lake. It enables a much easier way to store and access the data. Azure Data Lake Storage Gen2 is the current implementation of Azure’s Data Lake storage. An Azure Data Lake is essentially a distributed file system and therefore there are multiple layers.
- Raw – The staging area from incoming data sources where the data is raw
- Enriched – Raw data is cleaned and possibly filtered/transformed
- Curated – Data is ready to be consumed
Transform/Enrich
To move the data from Data Lake’s raw layer to enriched and finally to the curated layer for consumption, use serverless SQL queries, spark notebooks and data flows for required data validations and transformations. Data explorer pools help explore logs and IoT data for streaming datasets and also perform time-series analysis. Machine-learning models can be invoked during transformation to get further insight into your data.
Azure Synapse SQL is a SQL engine that distributes data computation across multiple nodes in a scale-out architecture (Remember – Compute is separate from Storage in the cloud world). Using standard SQL, you can query data from a wide variety of sources including data lakes, data warehouses, and operational databases. There are two options for Synapse SQL.
- Dedicated SQL pool (formerly Azure SQL DW)- Fully managed enterprise data warehouse that supports MPP (Massively Parallel Processing). A Synapse SQL pool is provisioned with CPU, memory, and IO which are bundled into Data Warehouse Units (DWU) to help scale computations. The higher the DWUs, the higher the performance is but comes at an added computational cost which however will not impact your storage cost. The unit of scale here is Data Warehouse Units. The large volume of data can be imported into the dedicated SQL pool using SQL which then with the help distributed query engine allows to run high performance analytics. A key benefit of using a dedicated pool is the ability to temporarily stop the resources to save costs.
- Serverless SQL Pool – A tool to run queries against data stored in the data lake (Parquet, Delta Lake), Azure Cosmos DB, or Dataverse without the need to load the data into a specific layer. Resources are automatically scaled based on workloads and charged for only the queries it run.
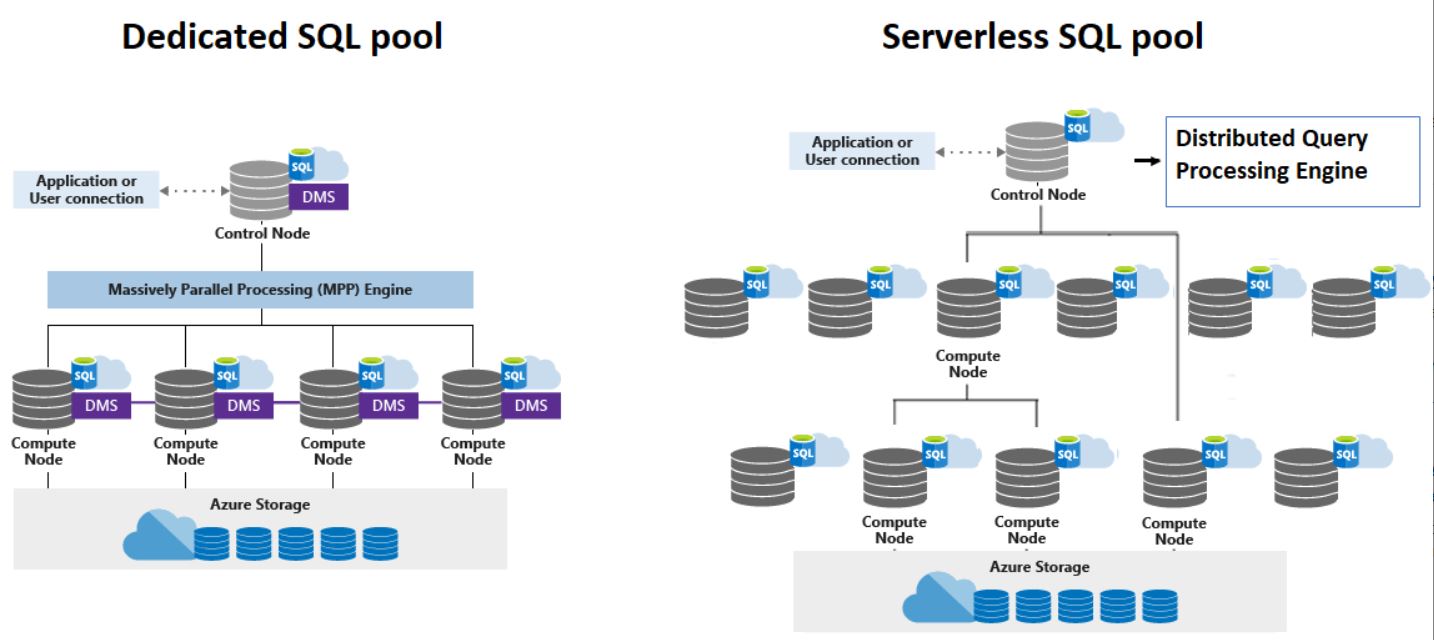
Image Source: Synapse SQL pool using Control and Compute nodes
Control Node: The brain of Synapse SQL’s node-based architecture and is the only entry point into Synapse SQL.
Compute Node: It stores all user data in Azure storage and provides compute power depending on the available nodes. The Data Movement Service (DMS) helps move the data across the compute nodes to run parallel queries.
Spark pools
Apache Spark is a framework for large-scale data analytics. Microsoft has integrated a version of Apache Spark in Azure Synapse Analytics which makes it easier to create and configure a serverless Apache Spark Pool in Azure. It comes with support for Python, R, and Scala. You can leverage the power of Apache Spark’s highly scalable distributed engine for data engineering in Azure Synapse using Spark notebook.
Serve
Data for consumption to Power BI for visualization can be shared directly from the curated layer in the data lake. If a consumer-driven semantic model needs to be built to support further analysis and visualization, load the data into the Power BI dataset. Azure Data Share can be used to securely share data with both internal and external people. AI and data mining models can be built leveraging data available in Synapse.
Important Notes
- Azure Analysis Services: If your current solution uses Azure Analysis Services (AAS), a fully managed PaaS to build enterprise data models then it is time to migrate AAS databases to Power BI Premium. Power BI has been central in delivering enterprise-grade BI and Microsoft has been delivering AAS features to Power BI Premium. The current feature sets, workloads, and capabilities within Power BI exceed any comparable features available in AAS or even SSAS.
- Data Lake VS Data Warehouse: A data lake is a scalable data store that can hold data in its original format whether they are structured or unstructured. Those raw data are further transformed and enriched for consumers. On the other side, a data warehouse has data processed and transformed for further analysis. Data lake and warehouse complement each other where data lake allows the companies to store their large volume of raw data and data warehouse provides enriched data in a more structured format for further analysis.